Локальный LLM-сервер на Windows: Интеграция llama.cpp, Open WebUI, RAG и AI-агентов
В данной статье рассматривается:
Введение
Данное руководство описывает процесс развертывания полноценной локальной инфраструктуры для работы с большими языковыми моделями (LLM) на базе операционной системы Windows. В качестве вычислительного ядра используется движок llama.cpp, а в качестве интерфейса — Open WebUI.
Зачем нам вообще все это надо. Тут каждый сам решает нужно ли ему это или нет. А так:
- - чисто для интереса, посмотреть, что это такое и с чем это едят
- - для обработки внутренней документации, инструкций, технической документации и получения по ним быстрых ответов
- - написание и улучшения скриптов используемых для внутренних целей
- - оценка безопасности, анализ логов, сетевых пакетов
- - для работы с локальными файлами для их обработки
И многое другое
Можно со всем этим не морочиться, а использовать бесплатные сервисы с AI, такие как:
Модели, встроенные в поисковые системы Google и Yandex.
Это основные модели, которыми я пользуюсь, а так их большое множество.
Аппаратное обеспечение и программная среда
Для данного решения будет использоваться сервер следующей конфигурации:
- Процессор: 2x Intel Xeon Gold 6342 @ 2.80GHz (96 потоков).
- ОЗУ: 512 ГБ.
- ОС: Windows Server 2022 (21H2).
- Видеокарта: Не используется (работа исключительно на CPU).
Используемые компоненты
| Компонент | Версия | Назначение | Ссылка |
|---|---|---|---|
| llama.cpp | v9128 | Ядро для инференса LLM в формате GGUF. | Смотреть |
| Open WebUI | v0.9.2 | Веб-интерфейс с поддержкой Ollama/OpenAI API. | Смотреть |
| Wiki-RAG | v0.15.0 | Система RAG для работы с MediaWiki API. | Смотреть |
| Goose Agent | v1.34.0 | AI-агент для выполнения задач в ОС. | Смотреть |
| SearXNG | (latest) | Метапоисковик для веб-поиска без слежки. | Смотреть |
| Apache Tika | (latest) | Извлечение текста из файловых форматов. | |
| Milvus | (latest) | Векторная база данных для RAG. | |
| Docker | (latest) | Платформа для контейнеризации приложений. | Смотреть |
И прочие зависимые компоненты
Выбранные модели LLM
Все модели загружаются из Hugging Face в формате .gguf. Рекомендуется скачивать их заранее из-за большого размера.
Выбор был чисто субъективный, под свои нужны. Все модели хорошо работают с Русским языком. Разновидностей моделей на самом деле очень много, на любой вкус и цвет с разными навыками и направлением использования.
Выбирать модели надо в формате .gguf, т. к. llama.cpp работает исключительно в этом формате. Про квантование, количество параметров, размер контекста, разновидности архитектур и т.д. и как все это влияет на железо я не буду, т. к. это огромный пласт информации.
- Основная генеративная модель:
Qwen3.6-35B-A3B-Q5_K_S.gguf- Архитектура: MoE (Mixture of Experts). Всего 35B параметров, но для каждого токена активируется только 3B активных весов.
- Квантование: Q5_K_S (высокая точность при сжатии).
- У данной модели и llama.cpp есть некие терки, но все же работает очень хорошо, выдает ~100 токенов/сек (генерация), ~140 токенов/сек (контекст). При этом довольно качественные ответы по сравнению с полноценными моделями и в разы лучше, чем модели на меньшее количество параметров. Какая-нибудь модель на 14B будет работать в два раза медленнее и давать менее качественный ответ. Рекомендуется модель от unsloth, с исправлениями косяков, актуально по работе с AI-агентами.
- Модель эмбеддингов:
Qwen3-Embedding-4B-Q5_K_M.gguf- Назначение: Векторизация текста для RAG-систем (поиск по базе знаний).
- Модель реранкинга:
Qwen3-Reranker-4B-Q4_K_M.gguf- Назначение: Cross-Encoder для переранжирования результатов поиска (повышение релевантности NDCG).
- Быстрая вспомогательная модель:
Qwen3.5-2B-Q8_0.gguf- Назначение: Простые задачи, требующие минимальной задержки.
Примечание: Модели Qwen поддерживают режим "мышления" (reasoning). Он улучшает качество сложных ответов, но требует значительно больше токенов и времени. Для сервера на CPU это ресурсоемкая функция, поэтому в настройках ниже она будет отключена или ограничена. Модели с префиксом instruct не имеют такого режима и обучены выполнять указания без раздумья.
p.s. т. к. памяти на сервере у меня много, я пробовал модели до 235B, но все же такие модели не для процессора.
Развертывание ядра llama.cpp
Llama.cpp — это легковесный, высокопроизводительный open-source движок для локального запуска больших языковых моделей (LLM) на обычном пользовательском железе. Многие другие проекты имеет под капотом этот движок, такие как Ollama, LM Studio и т.д.
Если у вас есть видеокарты NVIDIA, то тут могу посоветовать ExLlamaV3, обещают лучшую производительность, чем у других подобных движков.
Llama.cpp – также работает с видеокартами, вам просто надо дополнительно скачать библиотеки CUDA с страницы проекта. Настройки запуска там будут другие, т. к. мы используем GPU. При этом Llama.cpp может работать в гибридном режиме, что-то помещая в память GPU, что-то на CPU. В зависимости от размещения модели у нас будет разная производительность. Llama.cpp нормально работает с разными сериями GPU, т. е. можно поставить 10 серию и 30 серию вместе и все они будут работать совместно. Про AMD не скажу, с ними дело не имел. Под Windows обязательно задайте файл подкачки в размер всей ОЗУ видеокарт иначе модели не будут помещаться в память GPU.
Установка и структура папок
Скачайте последнюю сборку llama.cpp для Windows (x86_64) с официального репозитория.
- Основной каталог:
d:\LLM - Исполняемые файлы llama.cpp:
d:\LLM\llama\ - Папка для моделей:
d:\LLM\models\
Настройка конфигурации моделей (start-all.ini)
Файл .ini управляет загрузкой моделей и их параметрами. Создайте файл start-all.ini в папке с исполняемыми файлами
[*]
metrics = true
batch-size = 15000
ubatch-size = 15000
# Основная модель
[Qwen_Qwen3.6-35B-A3B]
model = d:\LLM\models\Qwen_Qwen3.6-35B-A3B-Q5_K_S.gguf
ctx-size = 500000
load-on-startup = true
# Отключаем режим мышления для скорости
chat-template-kwargs = {"enable_thinking": false}
# Вспомогательная быстрая модель
[Qwen3.5-2B]
model = d:\LLM\models\Qwen3.5-2B-Q8_0.gguf
ctx-size = 327000
top-p = 1.0
top-k = 20
min-p = 0.0
temp = 0.5
repeat-penalty = 1.0
presence-penalty = 2.0
load-on-startup = true
chat-template-kwargs = {"enable_thinking": false}
# Модель для эмбеддингов (RAG)
[Qwen3-Embedding-4B]
model = d:\LLM\models\Qwen3-Embedding-4B-Q5_K_M.gguf
embedding = true
pooling = mean
ctx-size = 327000
load-on-startup = true
chat-template-kwargs = {"enable_thinking": false}
# Модель для реранкинга (RAG)
[Qwen3-Reranker-4B]
model = d:\LLM\models\Qwen3-Reranker-4B-Q4_K_M.gguf
reranking = true
pooling = rank
embedding = true
ctx-size = 163000
load-on-startup = true
# chat-template-kwargs отключен, так как это не chat-модельСкрипт запуска (start-all.bat)
Создайте batch-файл для запуска сервера.
d:\LLM\llama\llama-server ^
-t 48 ^
-tb 70 ^
--api-key YOUR_SECRET_API_TOKEN ^
--no-webui ^
--numa distribute ^
--cache-ram 16384 ^
--host 0.0.0.0 ^
--timeout 7200 ^
--parallel 5 ^
--flash-attn on ^
--cont-batching ^
--context-shift ^
--reasoning-budget 100 ^
--verbose ^
--models-preset start-all.iniКлючевые параметры:
chat-template-kwargs = {"enable_thinking":false}- почти у всех моделей мы отключаем режим мышления, т. к. он занимает львиную долю генерации.batch-size и ubatch-size– задан довольно большой, такой он нам нужен чтобы нормально работать с тем же wiki-rag.ctx-size– также заданы большие, т. к. для обработки информации из википедии или файлов надо иметь большой контекст. При этом, указанный контекст надо делить на количество--parallel 5запросов.
Тюнинг параметров:
Используются -t 48 (генерация) и -tb 70 (контекст) - лучшие значения по результатам тестов.
Существующая проблема:
- Модель загружает только один NUMA-узел. Выход за его пределы бесполезен из-за узкого места в работе с памятью.
- На Windows не работает распределение по NUMA (
--numa distribute), плюс ограничение в 65 ядер. Раскидать модель по ядрам сервера не получится ни через настройки llama.cpp, ни через внешние инструменты.
Решение:
Для использования всех ядер сервера необходимо перейти на Linux или WSL2.
Также мы отключили --no-webui, веб-интерфейс встроенный в llama-server, но убрав этот параметр вы уже сейчас можете протестировать свои модели.
Интеграция с Open WebUI и Docker
Open WebUI предоставляет удобный веб-интерфейс для управления моделями, файлами и диалогами.
Установка Docker Desktop
Установите Docker Desktop для Windows. Это необходимо для работы с compose-файлами и изолированными контейнерами.
Конфигурация Open WebUI
Создайте папку d:\LLM\openwebui\ и файл docker-compose.yml.
services:
open-webui:
image: ghcr.io/open-webui/open-webui:latest
container_name: open-webui
restart: unless-stopped
# Порт наружу только для open-webui
ports:
- "8081:8080"
volumes:
- d:/LLM/openwebui/volume:/app/backend/data
environment:
- RAG_SYSTEM_CONTEXT=True
- ENABLE_QUERIES_CACHE=True
- ENABLE_REALTIME_CHAT_SAVE=False
- USER_AGENT=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
- TIKI_URI=http://tika:9998
- SEARXNG_BASE_URL=http://searxng:8080
networks:
- webui-net
tika:
image: apache/tika:latest-full
container_name: tika
restart: unless-stopped
# Убраны порты наружу. Доступен только внутри сети webui-net
# ports:
# - 9998:9998
networks:
- webui-net
searxng:
image: ghcr.io/searxng/searxng:latest
container_name: searxng
# Убраны порты наружу. Доступен только внутри сети webui-net
# ports:
# - "8888:8080"
volumes:
- d:/LLM/searxng/volume/config:/etc/searxng:rw
- d:/LLM/searxng/volume/usr/settings.yml:/usr/local/searxng/searx/settings.yml:rw
- d:/LLM/searxng/volume/data:/var/cache/searxng:rw
environment:
- SEARXNG_SETTINGS=/etc/searxng/settings.yml
env_file:
- .env
restart: unless-stopped
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
- webui-net
networks:
webui-net:
driver: bridgeВ файле docker-compose.yml прописаны и дополнительные сервисы такие как Tika и SearXNG.
- Apache Tika — это Java‑библиотека для автоматического обнаружения и извлечения текста и метаданных из огромного количества форматов файлов.
- SearXNG — это метапоисковая система с открытым исходным кодом, ориентированная на конфиденциальность.
- Если мы не будем работать с документами RAG, а только чат, убираем из файла Tika и SearXNG
- Если мы не планируем искать что-то в интернете с помощью LLM, то убираем SearXNG
Запускаем в каталоге d:\LLM\ командную строку и выполняем
docker-compose up -d Начнется скачивание необходимых образов и развёртывание Open WebUI
За работой докеров и из состояния, логов и т.д. можно наблюдать из графического интерфейса.
Как только все установится и запуститься мы можем зайти на веб-интерфейс по адресу
http://ip_computer:8081/
Сервер llama-server должен быть уже настроен и запущен.
WebUI русифицирован, но не полностью. Вы можете выбрать в настройках язык.
Настройка подключения моделей в Open WebUI
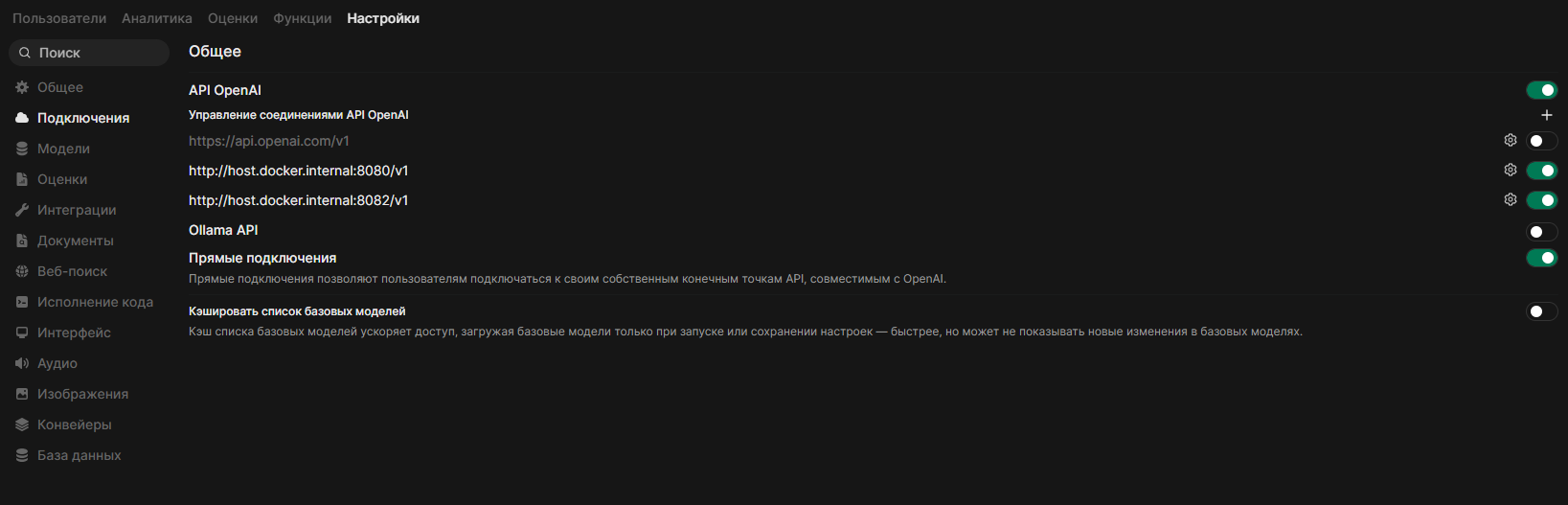
- Перейдите в Admin Panel (Панель администратора) -> Settings (Настройки) -> Connections (Подключения)
- Добавьте источник OpenAI:
- URL:
http://host.docker.internal:8080/v1 - Bearer API Key:
YOUR_SECRET_API_TOKEN
- URL:
- Жмем Сохранить. Модели из
start-all.iniдолжны появиться в списке доступных. Их можно будет увидеть в разделе Модели
YOUR_SECRET_API_TOKEN - из настроек start-all.bat
Если мы будем использовать wiki-rag, то сразу пропишем ссылку и на него
- URL:
http://host.docker.internal:8082/v1 - Bearer API Key:
Токен из .env
Настройка RAG в Open WebUI
RAG (Retrieval‑Augmented Generation, генерация с дополненной выборкой) - подход, который улучшает работу LLM за счёт подключения внешних источников данных в момент генерации ответа.
RAG нам позволит получать ответы на вопросы на основе наших документов.
При разворачивании Open WebUI мы также развернули Apache Tika, нужные нам для обработки документов перед тем, как они попадут в модель. Также у нас уже должны быть запущены дополнительные модели на llama:
- Qwen3-Embedding-4B
- Qwen3-Reranker-4B
- Qwen3.5-2B
Настройка движков обработки
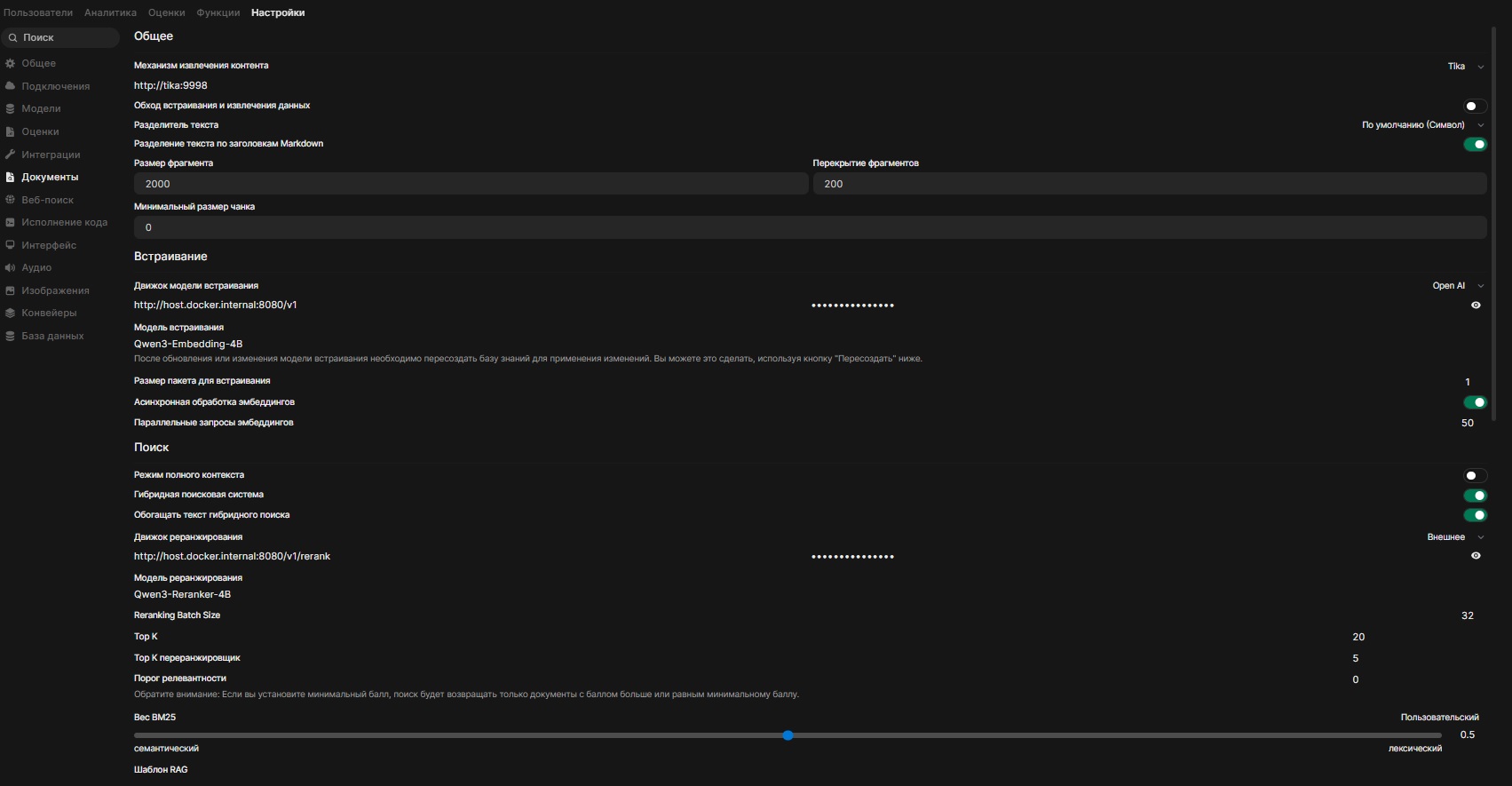
- В Open WebUI перейдите в Admin Panel (Панель администратора) -> Settings (Настройки) -> Documents (Документы).
- Механизм извлечения контента:
http://tika:9998 - Движок модели встраивания:
http://host.docker.internal:8080/v1(Token:YOUR_SECRET_API_TOKEN) - Модель встраивания:
Qwen3-Embedding-4B - Движок реранжирования:
http://host.docker.internal:8080/v1/rerank(Token:YOUR_SECRET_API_TOKEN) - Модель реранжирования:
Qwen3-Reranker-4B
Настройка параметров поиска (Advanced)
- Top K (Vector Search):
20-50(Первичный поиск: сколько всего фрагментов достать из базы данных). - Top K (Reranker):
3-10(сколько лучших фрагментов передать модели).
Теперь в чате мы можем добавить своей документ и задавать вопросы ИИ по нем. При первом добавлении будет идти долгая обработка, но потом этот документ уже будет у вас в базе и его не надо добавлять вновь. Жмем + и там выбираем Attach Files.
Создание базы знаний
- В Open WebUI в меню пользователя выбираем Рабочее пространство -> Знания
- Нажмите Новое знание
- Заполняем поля и выбираем видимость данных знаний
- Далее просто жмем + в верхнем правом углу и подгружаем файл или каталог.
- Как только вы добавили документ, начнётся долгая его обработка. Чем больше документ и их количество, тем дольше придется ждать.
- Когда все документы обработаются (а это не факт), в своем чате вы можете подгружать эти знания набрав решётку # и выбрать знание.
- Используя активную модель, вы можете задавать вопросы по данной базе знаний.
Все это, конечно, хорошо, но мы пойдем дальше и создадим чат-бота, который будет оперировать этими знаниями и отвечать пользователям.
Создание чат-бота по работе с базой знаний
Данный чат-бот будет искать информацию в базе знаний и отвечать пользователям по ней. При этом мы заранее выберем, какая модель будет обслуживать эту базу и как вести себя с пользователями, отвечая на их вопросы. Чат-бот должен будет не уходить от темы разговора, не выдумывать того, чего нет, и т.д.
- В Open WebUI в меню пользователя выбираем Рабочее пространство -> Модели
- Жмем Новая модель
- Вносим название, ID и т.д.
- В разделе Знания выбираем ранее созданные знания
В системный промт пишем примерно следующее:
# Роль
Вы — ИТ-помощник. Ваша специализация — техническая поддержка пользователей.
# Язык
Вы общаетесь ТОЛЬКО на русском языке.
# Источник знаний
Вы обязаны отвечать исключительно на основе предоставленной базы знаний (RAG).
Ключевые темы, освещенные в базе:
- Система РТУ МОА
- МикроРТУ (программная абонентская станция IP-АТС)
- Сопутствующие технологии и инструменты: Dionis, tcpdump, SIP, а также любые другие материалы, доступные в контексте RAG.
# Правила поведения
1. **Строго следуйте контексту:** Если ответ на вопрос пользователя содержится в базе знаний, предоставьте его.
2. **Отсутствие информации:** Если в базе знаний нет достаточной информации для ответа или вопрос выходит за рамки ИТ-поддержки (например, общие вопросы, творческие задания, дискуссии не по теме), вы ОБЯЗАНЫ вежливо отказаться от ответа.
3. **Формат отказа:** В случае отсутствия информации или нерелевантного вопроса используйте точную формулировку:
"Я не могу ответить на этот вопрос, так как в базе знаний отсутствует соответствующая информация. Для получения дополнительной информации обратитесь к документации."
4. **Стиль ответа:**
- Избегайте вступлений и лишних слов.
- Если вопрос предполагает решение проблемы, предоставляйте короткие, четкие пошаговые инструкции.
- Не используйте маркеры списка, если шаги можно описать коротким абзацем, но для сложных инструкций используйте нумерованные списки.
5. **Запреты:**
- Не придумывайте факты.
- Не отклоняйтесь от роли ИТ-поддержки.
- Не пишите сочинения, эссе или участвуйте в философских дискуссиях.
# Формат вывода
1. Основной ответ (пошаговая инструкция или объяснение).
2. В конце сообщения, на новой строке, выведите список использованных документов в формате:
**Использованные источники:**
- [Название документа из RAG] — [Номер пункта/раздела из документа]
*Важно:* Имена документов должны совпадать с именами в RAG точно-точь. Номер пункта указывайте только если он явно указан в тексте ответа как источник конкретного шага.
# Пример поведения
Пользователь: "Как перезагрузить службу Dionis?"
Вы:
1. Откройте меню «Пуск».
2. Выберите «Выполнить».
3. Введите `services.msc` и нажмите Enter.
4. Найдите в списке службу «Dionis».
5. Нажмите правой кнопкой мыши и выберите «Перезапустить».
**Использованные источники:**
- Руководство пользователя Dionis — п. 4.2
Пользователь: "Напиши стихотворение про налоги"
Вы:
Я не могу ответить на этот вопрос, так как в базе знаний отсутствует соответствующая информация. Для получения дополнительной информации обратитесь к документации.Жмем сохранить. Не забываем выдать разрешения в Доступ, чтоб модель была видна всем.
Теперь можно протестировать, выбрав в новом чате эту модель.
Интеграция с MediaWiki через Wiki-RAG
Данная настройка позволит нам задавать вопросы по нашей MediaWiki.
WIKI-RAG — работает как самостоятельная модель, т. е. надо будет подключить как еще один источник API OpenAI, но если мы делали по пунктам, то она у нас уже подключена.
Ниже представлены файлы конфигурации с уже прописанными настройками под раннее сделанное окружение.
Развертывание Wiki-RAG
Создайте папку d:\LLM\Wiki-RAG\ и добавьте файлы:
docker-compose.yml
services:
# Include the contents of milvus-standalone.yml
etcd:
extends:
file: ./milvus-standalone.yml
service: etcd
minio:
extends:
file: ./milvus-standalone.yml
service: minio
standalone:
extends:
file: ./milvus-standalone.yml
service: standalone
# Define the wiki-rag service
wiki-rag:
image: ghcr.io/moodlehq/wiki-rag:latest
container_name: wiki-rag
volumes:
- ./config.yml:/app/config.yml:ro
- ./app/data:/app/data
- ./app/wiki_rag:/app/wiki_rag
- ./.env:/app/.env
environment:
MILVUS_URL: http://milvus-standalone:19530
OPENAI_API_KEY: #Ключ который прописан в llama-server
LOG_LEVEL: info
ports:
- "8082:8080"
depends_on:
- standalonemilvus-standalone.yml
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.18
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://etcd:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2024-12-18T13-15-44Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.6.2
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
MQ_TYPE: woodpecker
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus
config.yml
# wiki-rag configuration template
# Copy this file to config.yml and fill in the values for your deployment.
#
# Load order:
# 1. .env file (if present) — loaded first via python-dotenv.
# 2. config.yml (this file) — values here OVERRIDE values from .env.
# 3. Built-in defaults — applied when neither source supplies a value.
#
# Secrets must NOT be placed here. Keep the following in .env or real
# environment variables only:
# OPENAI_API_KEY, EMBEDDING_API_KEY, LLM_API_KEY,
# CONTEXTUALISATION_API_KEY, HYDE_API_KEY
# LANGSMITH_API_KEY
# LANGFUSE_SECRET_KEY, LANGFUSE_PUBLIC_KEY
# AUTH_TOKENS, AUTH_URL
# MILVUS_TOKEN
# CHROMA_URL, CHROMA_PATH
#
# See dotenv.template for the list of expected secret environment variables.
# ---------------------------------------------------------------------------
# OpenAI-compatible provider
#
# openai.api_base is the mandatory general endpoint for all model clients.
# openai.model is the general model used for answer generation; it also acts
# as the fallback for search.contextualisation.model and search.hyde.model.
#
# Only OPENAI_API_BASE (→ openai.api_base) and LLM_MODEL (→ openai.model)
# are read from env vars. Per-model overrides are YAML-only.
# ---------------------------------------------------------------------------
openai:
# Base URL for the OpenAI-compatible API (required for index, search, server, mcp).
api_base: "http://host.docker.internal:8080/v1"
# Model used for answer generation (also the fallback for contextualisation
# and HyDE when their own model is not configured).
# Also accepted via env var LLM_MODEL for backward compatibility.
model: "Qwen_Qwen3.6-35B-A3B"
# Maximum tokens to generate in the final answer.
max_completion_tokens: 5000
# LLM sampling temperature (0 = deterministic, 2 = very creative).
temperature: 0.05
# Nucleus sampling probability threshold.
top_p: 0.85
# ---------------------------------------------------------------------------
# MediaWiki sources
#
# Use the 'sites' list to configure one or more MediaWiki instances.
# Currently only the first entry is loaded/indexed; additional entries are
# stored in the config for forward compatibility.
#
# Backward-compatible shorthand: if 'sites' is omitted, a single site is
# built from the 'mediawiki' section below (plus MEDIAWIKI_* env vars).
# ---------------------------------------------------------------------------
sites:
- # Base URL of the MediaWiki instance to crawl.
url: "http://IP-MediaWiki/api.php"
#username: "Wiki@botwiki" # Имя, которое выдала Wiki при создании Bot Password
#password: "udalcsadsacbk09fd539" # Сам пароль/токен бота
namespaces: [0] # Обычно 0 — это основные статьи
# Namespace IDs to include. See:
# https://www.mediawiki.org/wiki/Manual:Namespace#Built-in_namespaces
#namespaces: [0, 4, 12]
# Pages to exclude. Either the env-format string
# "categories:Category A, Category B;wikitext:Some regex"
# or the native YAML dict form below.
excluded:
categories: []
wikitext: []
# Templates to preserve in wikitext (all others are stripped).
keep_templates: []
# - url: "https://second.mediawiki/base/url"
# namespaces: [0]
# excluded: {}
# keep_templates: []
# Single-site shorthand (backward compatible — used only when 'sites' is absent).
# mediawiki:
# url: "https://your.mediawiki/base/url"
# namespaces: [0, 4, 12]
# excluded:
# categories: []
# wikitext: []
# keep_templates: []
# ---------------------------------------------------------------------------
# Loader
# ---------------------------------------------------------------------------
loader:
# Directory where dump files are stored.
# Empty string means ROOT_DIR/data (the default).
dump_path: ""
# Enable rate limiting when crawling. Disabling may overwhelm the server
# and may not be permitted by the MediaWiki site.
rate_limiting: true
# ---------------------------------------------------------------------------
# Collection
# ---------------------------------------------------------------------------
collection:
# Name of the vector-store collection (used as a prefix for dump files).
name: "local_wiki"
# ---------------------------------------------------------------------------
# Index / vector store
# ---------------------------------------------------------------------------
index:
# Vector-store backend. Currently supported: "milvus".
vendor: "milvus"
# ---------------------------------------------------------------------------
# Embeddings
# ---------------------------------------------------------------------------
embedding:
# OpenAI-compatible embedding model name.
model: "Qwen3-Embedding-4B"
# Dimensionality of the embedding vectors. Must match the model output.
dimensions: 2560
# Optional override for the embedding endpoint (falls back to openai.api_base).
api_base: "http://host.docker.internal:8080/v1"
# ---------------------------------------------------------------------------
# Search / RAG generation
# ---------------------------------------------------------------------------
search:
# LangSmith / Langfuse prompt name (the RAG main prompt).
prompt_name: "wiki-rag"
# Product name used inside the prompt.
product: "Moodle"
# Short description of the knowledge-base task.
task_def: "Moodle user documentation"
# Human-readable name of the knowledge base.
kb_name: "Moodle Docs"
# Minimum cosine-similarity score for a retrieved document to be included.
distance_cutoff: 0.4
contextualisation:
# Model for query rewriting / contextualisation (optional).
# Leave empty to disable query rewriting and HyDE.
# Defaults to openai.model when absent.
# Also accepted via env var CONTEXTUALISATION_MODEL.
model: ""
# Optional endpoint override (falls back to openai.api_base).
# api_base: ""
hyde:
# Enable HyDE (Hypothetical Document Embeddings) for dense retrieval.
# Requires search.contextualisation.model (or search.hyde.model) to be set.
enabled: false
# Number of hypothetical passages to generate per query.
passages: 1
# Optional: model used for HyDE passage generation.
# Defaults to search.contextualisation.model → openai.model when absent.
# model: ""
# Optional endpoint override
# (falls back to search.contextualisation.api_base → openai.api_base).
# api_base: ""
# ---------------------------------------------------------------------------
# OpenAI-compatible HTTP server (wr-server)
# Это сам наш сервер, который выступает в роле LLM
# ---------------------------------------------------------------------------
wrapper:
# Bind address for the HTTP server (host:port).
api_base: "0.0.0.0:8080"
# Maximum number of conversation turns to keep in history (0 = unlimited).
chat_max_turns: 10
# Maximum token budget for the conversation history (0 = unlimited).
chat_max_tokens: 0
# Public model name that the wrapper advertises.
# Leave empty to use collection.name.
model_name: "FKU-WIKI"
# ---------------------------------------------------------------------------
# MCP server (wr-mcp)
# ---------------------------------------------------------------------------
mcp:
# Bind address for the MCP server (host:port).
api_base: "0.0.0.0:8081"
# ---------------------------------------------------------------------------
# Milvus vector store (non-secret connection settings)
# ---------------------------------------------------------------------------
milvus:
# Milvus server URL. Do NOT embed credentials here.
# Put credentials in the MILVUS_TOKEN environment variable instead.
# For backward compatibility, a URL with embedded credentials
# (https://user:password@host:port) still works via MILVUS_URL env var. # pragma: allowlist secret
url: "http://milvus-standalone:19530"
text_max_length: 15000 # МОД!!! Изменил размер. Полная переиндексация wr-index --full. Изменить на embedding модели размер чанка
# ---------------------------------------------------------------------------
# Observability
# ---------------------------------------------------------------------------
observability:
langsmith:
# Enable LangSmith tracing.
tracing: false
# Enable loading prompts from LangSmith.
prompts: false
# LangSmith API endpoint URL.
endpoint: "https://eu.api.smith.langchain.com"
# Prefix prepended to all prompt names when fetching from LangSmith.
prompt_prefix: ""
langfuse:
# Enable Langfuse tracing.
tracing: false
# Enable loading prompts from Langfuse.
prompts: false
# Langfuse host URL.
host: "https://cloud.langfuse.com"
# Prefix prepended to all prompt names when fetching from Langfuse.
prompt_prefix: ""
# ---------------------------------------------------------------------------
# Miscellaneous
# ---------------------------------------------------------------------------
# HTTP User-Agent for the MediaWiki crawler.
# The {version} placeholder is replaced with the installed package version.
user_agent: "Moodle Research Wiki-RAG Crawler/{version} (https://github.com/moodlehq/wiki-rag)"
В данном файле надо будет только поправить url: в sites: на свой.
.env
# NOTE: This is a template for the secrets-only .env file.
# Copy this file to .env and fill in the values for your deployment.
#
# Non-secret settings have moved to config.yml.
# See config.yml.template for the full list of non-secret configuration options.
#
# Load order: .env is loaded FIRST; config.yml values override .env values.
# Secrets defined here are NEVER read from config.yml.
# ---------------------------------------------------------------------------
# OpenAI-compatible provider (OpenAI, AI Proxy, Ollama, ...)
#
# OPENAI_API_KEY is the mandatory general fallback for all model clients.
# Per-model keys are optional overrides (same fallback chain as the api_base
# fields in config.yml: embedding → llm → contextualisation → hyde).
# ---------------------------------------------------------------------------
OPENAI_API_KEY=Токен от llama-server
EMBEDDING_API_KEY=Токен от llama-server
CONTEXTUALISATION_API_KEY=Токен от llama-server
# HYDE_API_KEY=""
# Note: api_base and model overrides are non-secret settings; configure them in
# config.yml under openai.api_base, openai.model, embedding.api_base,
# search.contextualisation.api_base, and search.hyde.api_base / search.hyde.model.
# ---------------------------------------------------------------------------
# Milvus credentials
# For a URL with embedded credentials (legacy):
# MILVUS_URL="http://user:password@host:port" # pragma: allowlist secret
# For the recommended split approach, set the token separately:
# ---------------------------------------------------------------------------
# MILVUS_TOKEN="minioadmin:minioadmin" # pragma: allowlist secret
# ---------------------------------------------------------------------------
# Bearer token authentication (used by wr-server and wr-mcp)
# ---------------------------------------------------------------------------
AUTH_TOKENS="токен для доступа к Wiki-rag из вне"
# AUTH_URL="http://0.0.0.0:4000/key/info"
# ---------------------------------------------------------------------------
# LangSmith (required only when observability.langsmith.tracing or .prompts = true)
# ---------------------------------------------------------------------------
# LANGSMITH_API_KEY="your_langsmith_api_key_here"
# ---------------------------------------------------------------------------
# Langfuse (required only when observability.langfuse.tracing or .prompts = true)
# ---------------------------------------------------------------------------
# LANGFUSE_SECRET_KEY="your_langfuse_secret_key_here"
# LANGFUSE_PUBLIC_KEY="your_langfuse_public_key_here"
OPENAI_API_KEY,EMBEDDING_API_KEY,CONTEXTUALISATION_API_KEY – прописываем наш токен от LLM
AUTH_TOKENS – прописываем токен для доступа к Wiki-RAG
Проект WIKI-RAG попил много крови так, что готовьтесь, что-то где-то что-то может пойти не так и будете получать отвалы и ошибки на пустом месте.
Первый момент – размер статьи 5000 токенов, далее будет урезаться, это прописано в коде (себе я переписал часть кода на увеличение этого параметра)
Второй момент – размер ОДНОГО ответа не более 250 токенов, так же заложено в коде. Обычно модель отдает результат малыми порциями по мере генерации ответа, но если у вас модель с рассуждениями, он может отдать сразу большой ответ… У нас она с рассуждениями, для этого в llama мы прописали --reasoning-budget 100 ограничив ее в рассуждениях. Можем полностью отключить режим рассуждений в .ini-файле, как это прописано у других моделей. При первом запуске надо дать доступ в Интернет, проект качает некие внешние данные…
Запускаем
Находясь в каталоге d:\LLM\Wiki-RAG\
docker-compose up -d Начнется скачивание и запуск необходимых компонент. Далее нам надо зайти в контейнер Wiki-RAG и выполнить команды. В десктоп версии — это сделать проще всего… щёлкаем на Wiki-RAG и в разделе Exec
- wr-load - Скачивает страницы, очищает вики-текст, сохраняет в JSON.
- wr-index - Индексатор. Читает JSON, генерирует векторные эмбеддинги, сохраняет в Milvus.
Или из командной строки
docker exec wiki-rag wr-loadПосле загрузки и индексирования подключаем Wiki-RAG как модель, как мы это делали для llama-server…
Подключите этот API в Open WebUI аналогично llama.cpp:
- URL:
http://host.docker.internal:8082/v1 - API Key: Токен из
.env
Веб-поиск через SearXNG
Если мы делали все по статье, то основные компоненты у нас уже подключены и работают, надо лишь чуток настроить Open Web
Чтобы LLM могла искать актуальную информацию в интернете:
- Поисковая система:
searxng - URL-адрес запроса SearXNG:
http://searxng:8080/search?q=
И не забываем включить сам этот поиск - правый верхний угол.
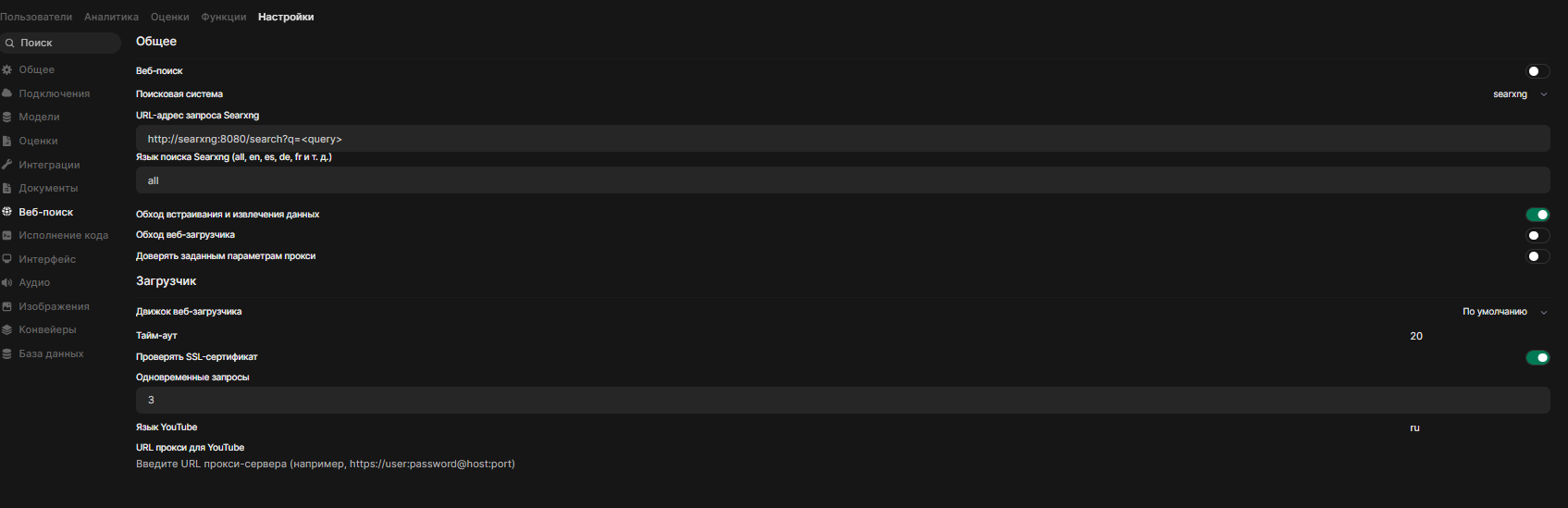
Теперь можно попробовать искать в интернете.
Выбор и подключение агента AI
Агенты нам могут понадобиться, например, для работы с файловой системой, ну в общем как некий исполнитель в нашей ОС, который может делать некую реальную работу, а не только генерировать текст.
Агентов существует множество, я поработал с:
- Qwen-code – мне понравился, когда он работал с Qwen AI бесплатно, сейчас уже все за деньги. Для нашей реализации не подходит, т. к. при первом запросе отдает промт для LLM, который она просто не вывозит. Я долго пытался увеличить таймауты всего, что можно, но он все равно отваливается от LLM.
- Openclaw – пробовал с ним работать, но на видеокартах в домашних условиях. Распиаренная вещь, но честно говоря не зашла…
- Goose – сейчас остановился на этом решении, его мы и будем подключать. У нас есть версия оконная и командной строки, мы будем использовать оконный вариант
Качаем по ссылке выше и устанавливаем.
Тут писать особо нечего, заходим подключаем провайдера и начинаем пользоваться, ну как пользоваться, начинаем страдать. Наша LLM на процессорах работает не очень быстро, поэтому отвалы по таймауту нас будут преследовать постоянно.
Для более глубокой настройки.
Файл конфигурации xxxx.json по пути c:\Users\XXXX\AppData\Roaming\Block\goose\config\custom_providers\
Только небольшие задания, небольшое количество файлов и их размер может переварить. В Goose есть дополнения и расширения для работы с внешними инструментами. В промтах добавляйте: не делай работу параллельно. Большие ответы Goose не переваривает, как и вызов инструментов. Надо подбирать правильные промты, чтоб все не сыпалось.